NUS CS2103T: Software Engineering
Everything to know before you get started




Introduction
CS2103T Software Engineering is one of the key computing modules you will take in your NUS Computer Science journey. Personally, it is one of the most interesting modules I have taken in NUS so far and really delves deep into the entire process of developing a software engineering product. This modules provides a great overview of what software engineering truly is about, giving you a high-level perspective on how to create a product from scratch.
In this article, I will cover the key concepts I learnt from CS2103T, helping you feel more prepared when it is your turn to take this module yourself. The aim of this article is not to be a complete cheatsheet of the entire module, but a general outline of the module’s content so that you know what to expect from CS2103T.
Content Page
SDLC Lifecycles
One of the first things we were taught from the module was the concept of Software Development Lifecycles (SDLC). SLDCs are basically the stages required to develop a software engineering product from scratch! For example, stages such as gathering requirements, designing architecture, implementation and testing are all part of the SDLC. There are some basic SDLC lifecycles covered in the module.
The Waterfall model depicts software engineering as a linear process. This means that the project progresses in one direction, from one stage to the next. As each stage of the model is completed, they should produce information that supports the next stage of development. This process is also named the sequential model.
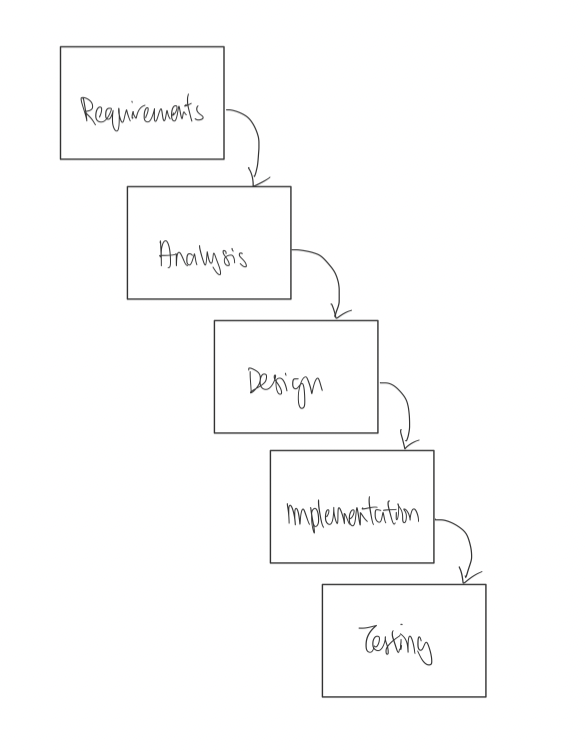
It is called the Waterfall model because the model flows from one stage to the next
The Waterfall model is mainly used when the problem statement is well-understood and stable from the start of development. This ensures that the entire project can be scoped and defined as one sequential model. However, the problem is that this is rarely the case in real-world projects.
The Iterative model depicts software engineering as several iterations of SDLCs. Basically, it involves developing multiple versions of the product. It can also be seen as several cycles of the Sequential model! This way, each version of the product can be improved on with feedback from the previous version. These improvements can include things like bug fixes or even additional product requirements.
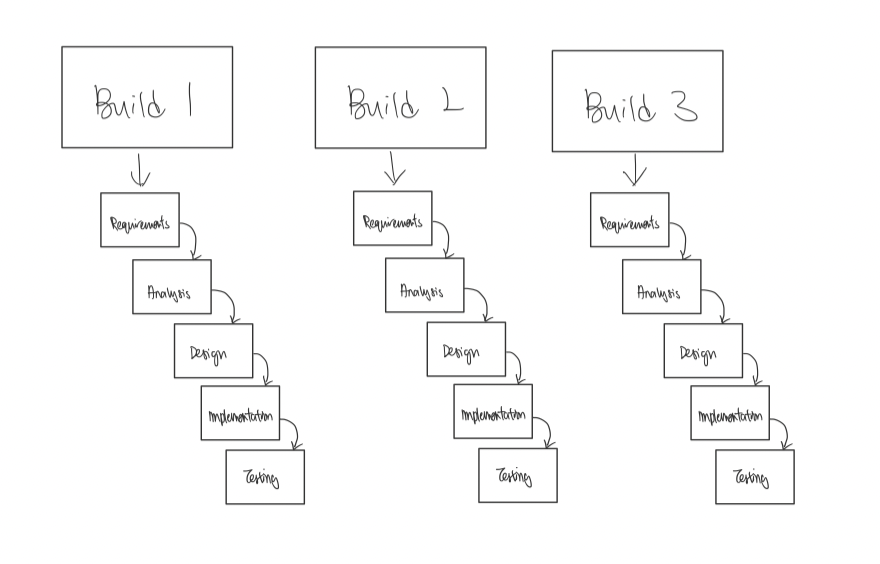
Iterative model includes creating several versions of the product
The Iterative model allows software engineers to have a polished version of the product at the end of each cycle. The key idea of this model is to be able to have a more and more complete version of the product at the end of each iteration. Additionally, you can define your problem statement and add on to it with each iteration, ensuring that your product improves with each version.
RCS
Revision Control Software (RCS) such as Git was also taught during the module. For those that are unfamiliar, RCS helps software engineers manage multiple versions of the product concurrently. This helps software engineers to safely coordinate large software engineering projects, while also ensuring that no past information is lost. A great example of RCS is actually Google Docs, whereby each change made to the document is saved by Google Docs itself, and the document can be retrieved to a previous state at any time.
Git is a RCS that most software engineers use around the world, and the basic functionalities of Git will be taught in the module as well. On Coding Cucumbers, we have many articles on the functionalities of Git which I highly suggest you check out to get familiarised with the software (Introduction to Git), but I’ll try to give a rough overview of what is taught in the module here.
Git is main RCS you will be using during the course of the module
In CS2103T, you will be working with remote repositories and learning to fork them into your Github and Clone them into your local computer. You will also learn to use the Forking Workflow while developing your team project, which requires you to keep your team’s official project in a remote repository, with all team members forking that repository and create pull requests from their own forks to the main repository to make any changes. Don’t be afraid if you’re unfamiliar with all these jargon as the module does a pretty good job at explaining everything!
Design Models
Design Models were also a big part of the module’s content. Design Models help software engineers represent problems and solutions in a more simplified form. They are useful when trying to explain complex entities, which is a common occurrence in the world of software engineering.
Three of the models taught in the module include Class Diagrams, Object Diagrams and Sequence Diagrams.
Class Diagrams help model the relationships between different Classes in the project. This can aid in explaining the role of each class. Class Diagrams can include the name, attributes and methods of each Class, but most importantly how each Class is related to another! These associations between Classes are key in using Class Diagrams to model a software engineering project.
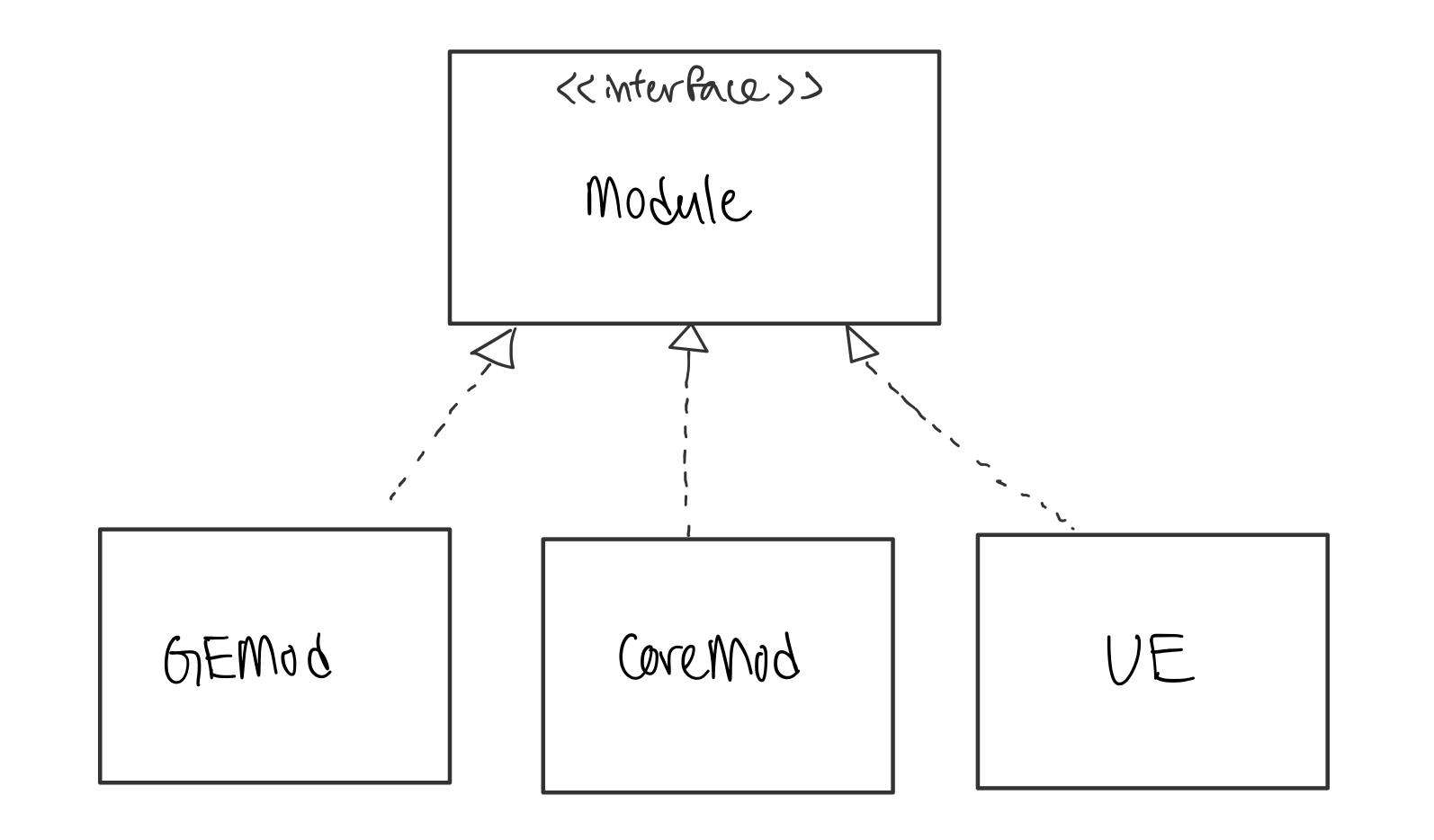
An example of a Class Diagram
Object Diagrams are similar to Class Diagrams, but help model the interactions between instances of Classes, instead of Classes itself. Basically, Object Diagrams are more like instances of Class Diagrams.
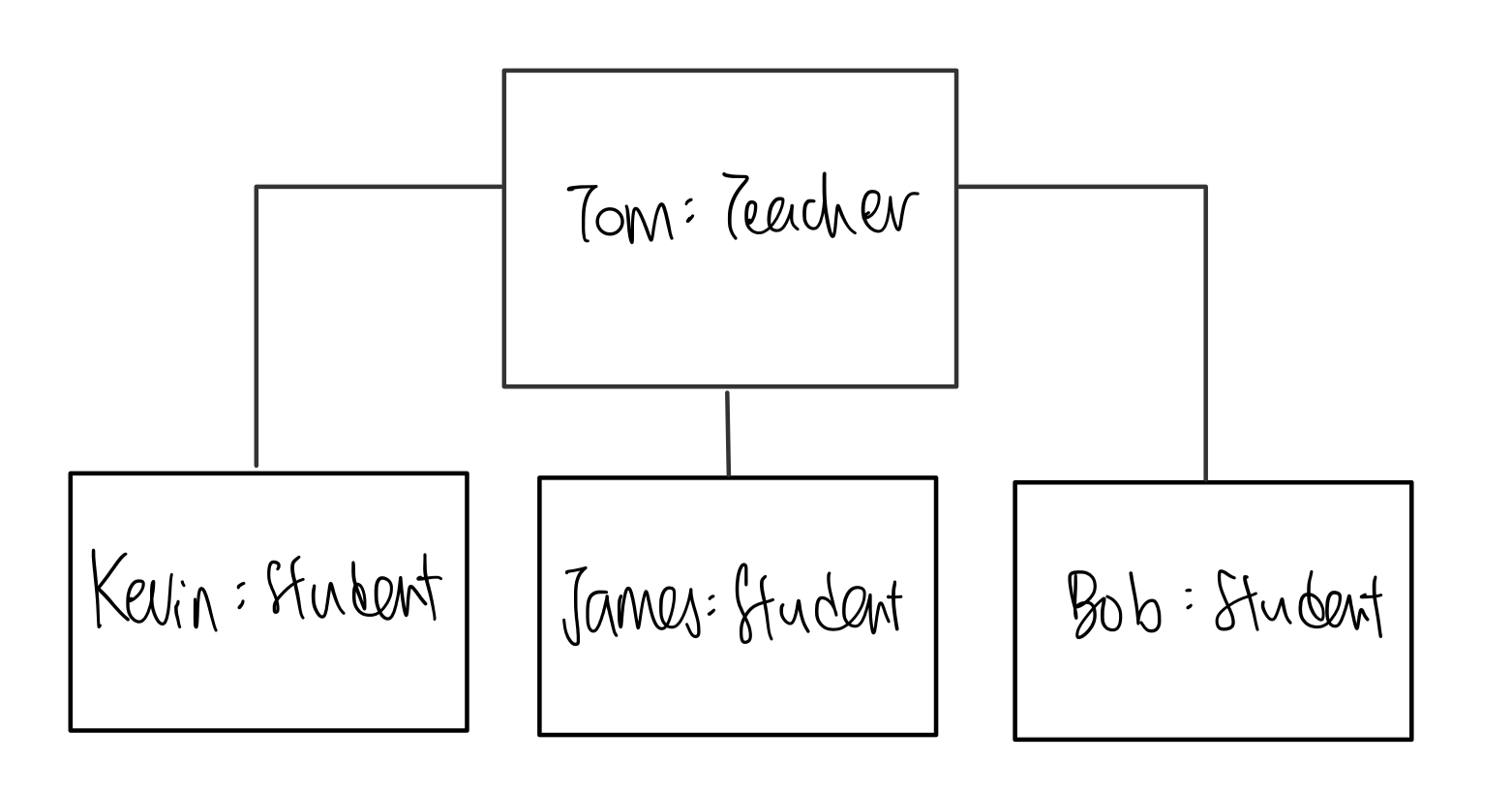
An example of an Object Diagram
Sequence Diagrams help model interactions between different entities in the project. These interactions mainly involve method calls and object creations! Basically, Sequence Diagrams help visualise the timeline of the interactions between objects in the project.
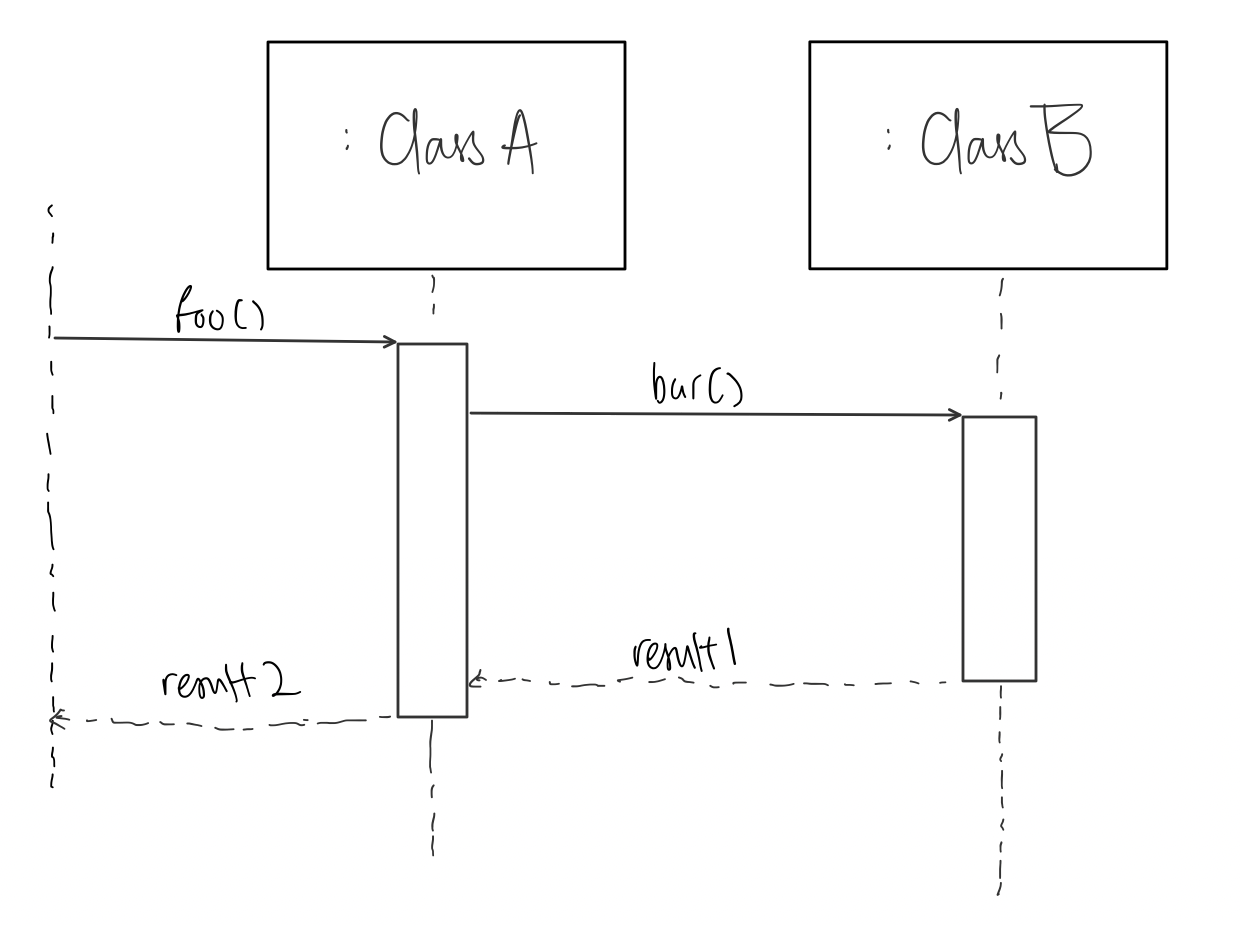
An example of a Sequence Diagram
These diagrams will be taught during the course of the module and you will be required to use these diagrams to describe your project as well.
Testing
Testing is also a big part of the module. Different types of testing will be taught in the module itself and the extent of your project’s testing is also part of your assessment for your team project. Testing your code requires you to compare the actual behaviour of your code versus the expected behaviour of your code. This way, we are able to identify bugs and fix them before releasing the version of the product.
Here are some types of testing covered in the module:
Unit testing is to test if each individual unit of the project works as expected. Each unit can refer to each class, method, subsystem etc.
Integration testing is to test if the different parts of a project work together. Integration testing hopes to find bugs in the code that “binds” different parts of the project together. Unlike Unit testing, Integration testing will involve code from different parts of the project.
Apart from the types of testing, the module also covers different methodologies when it comes to coming up with test cases. Although having a large number of test cases can mean more extensive testing, as software engineers we want our test code to be efficient and effective, and that requires us to put more thought into our test cases.
Some of the test case methodologies taught include:
Equivalence partitioning involves grouping sets of test cases together that are likely to be processed by the code in the same way. One example is if you have some code that processes strings of length 10 characters. One partition could include test cases with strings of length 9 and below, another partition could include test cases with strings of length 10, and another partition could include test cases with strings of length above 10!
Boundary Value Analysis involves test cases with values at the boundary of equivalence partitions. This is in the hopes of finding bugs that result from the code not handling values close to the boundaries of equivalence partitions correctly.
Project Scoping
Apart from the technical aspects, Software Engineering also involves scoping out the project and creating a product that people actually use. I especially found this aspect of the module interesting, especially when ideating and validating our team’s project. In the module, we were taught how to craft use cases and user stories which are vital to scope which features are key to our project.
Use cases are descriptions of a sequence of actions that a user performs to yield a result. Use cases help us to define what our application actually does, and be very clear on how they can carry out specific actions in our application.
An example use case can look like this:

An example use case of a note-taking application
A use case can include many additional information, such as extensions and preconditions to add more depth to each use case. However, at its core the use case should at least include the set of steps a user takes to do a specific action.
User stories are descriptions of an application’s feature, told from the point of view of a user. User stories help us sieve out what features are important to have in our application for our potential users, and what are the actual benefits gained by the users from each feature.
An example user story can look like this:

An example user story of a note-taking application
User stories are generally short and concise, however additional information can also be added to each user story (e.g. characteristics of specific user) to help round out the user story more. User stories can also be defined at various levels, with high-level user stories being called epics.
Design Patterns
Design Patterns are generally a solution that can be reused to solve a commonly occurring problem in software engineering. Although design patterns do not provide the actual solution to the problems, they help provide a “design” or “architecture” in which you can use to help build your code upon. The module covers many design patterns fairly extensively, so it's important to have a good understanding of all of them.
Singleton pattern refers to projects in which there are classes that should have no more than one instance (e.g. the main Controller class of the system). These instances are dubbed Singletons, and the Singleton pattern helps ensure that only one instance of these classes exists at any one point of time.
The Singleton pattern involves simple things such as making the constructor of the Singleton class private and providing a specific static method to access the single instance of the class. This ensures that no other instance of the class can be created, unlike if the constructor is left public.
MVC pattern refers to applications which support storage and retrieval of data, displaying of information to users, and changing data based on user inputs. Each of these actions can be controlled by a different component, namely the Model, View and Controller components.
The Model component should be in charge of the storage and accessing of data. It “models” the data of the application in the code, and should hold all the classes that controls the data necessary for the application to function.
The View component is basically the UI of the application, responsible of interacting with the user and pulling data from the Model component to display to the user.
The Controller component ties the Model and View components together, being in charge of detecting UI events and updating the Model and View components as necessary.
These design patterns are important to software engineers as they help solve commonly occurring problems in the development of most projects. Instead of “re-inventing the wheel”, many software engineers look to adopt some of these design patterns to help in the course of their development and can tremendously simplify many problems that they face.
Conclusion
All in all, CS2103T is an extremely important module for all Computer Science students. Before this module, our curriculum and modules focused heavily on highly technical skills and aspects of Computer Science. However, CS2103T really takes a bird’s eye view at the entire process of software engineering, and provides a very well-rounded understanding of software engineering in general.
The module will definitely prove useful to any prospective software engineers in the future, and will aid all NUS CS students in whatever internships they may pursue in the future. With that, stay cool cucumbers!